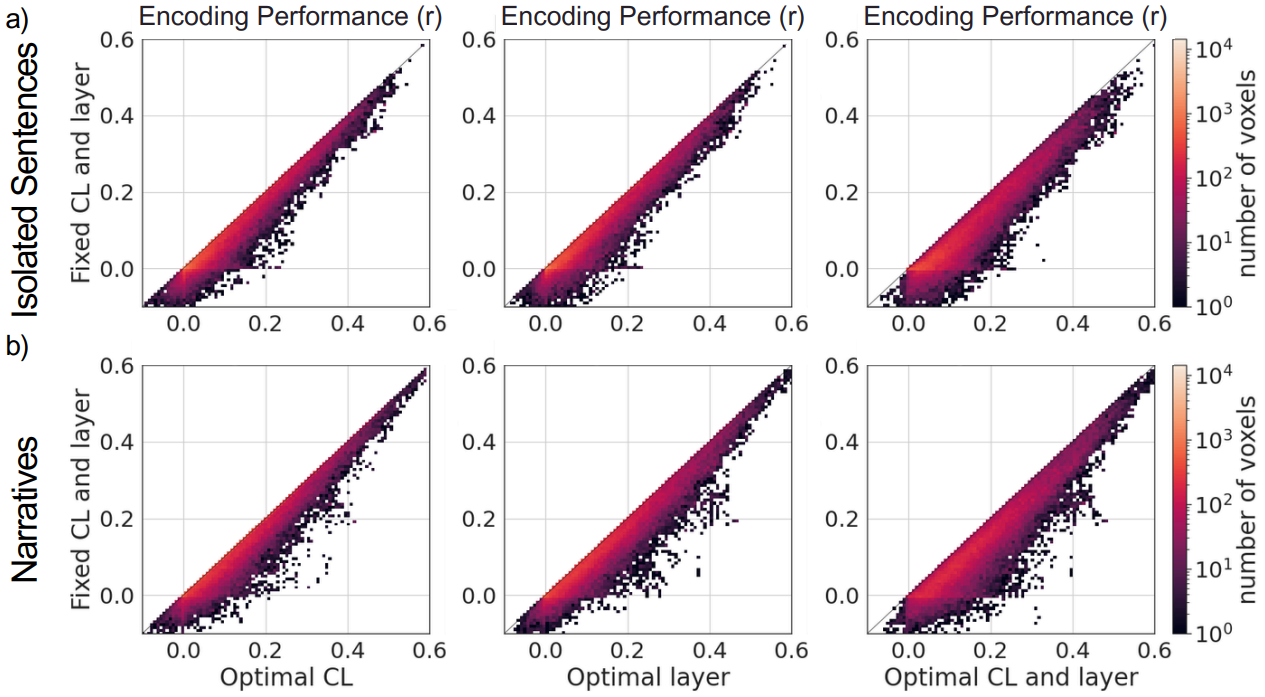
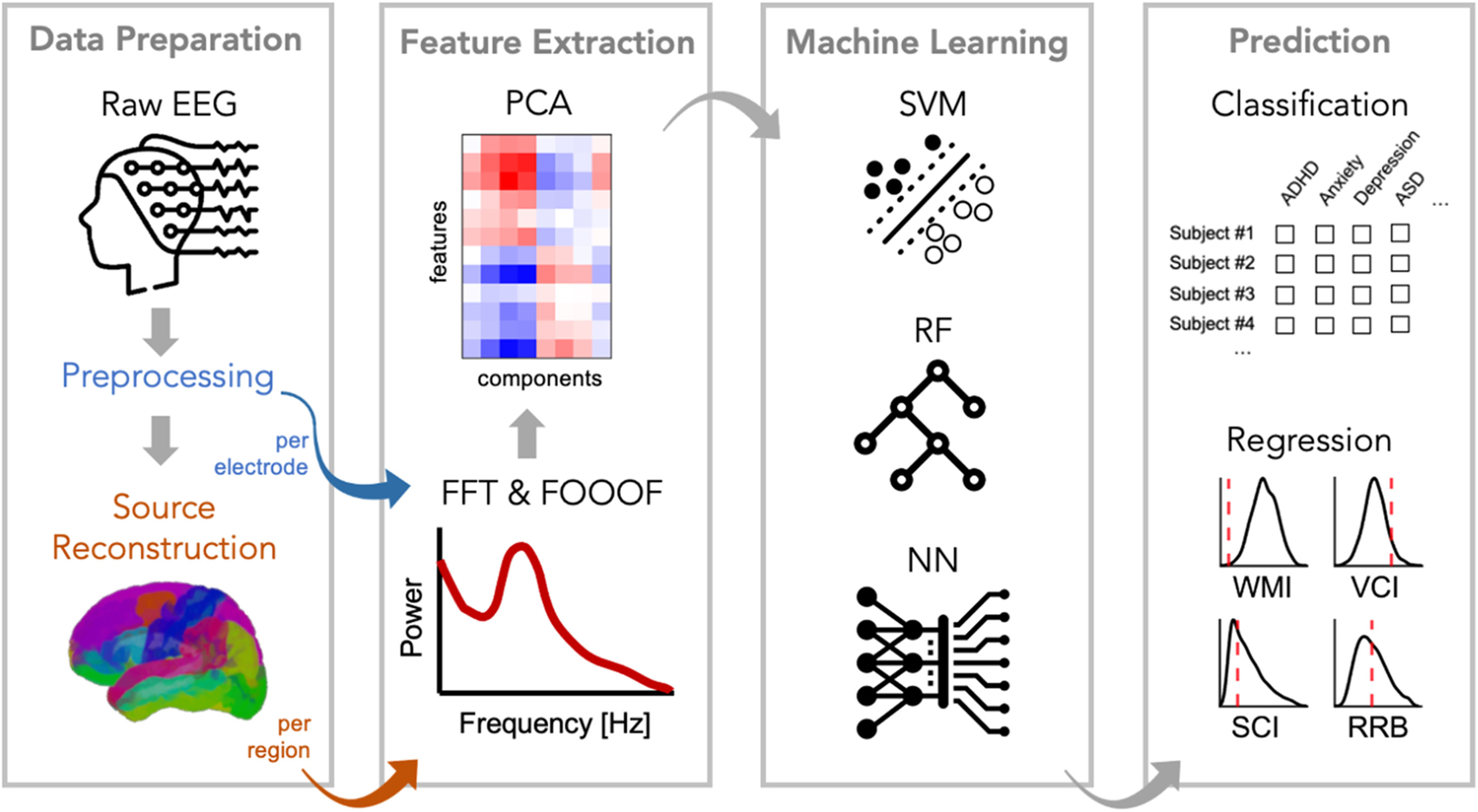
Recent studies have shown that contextual semantic embeddings from language models can accurately predict human brain activity during language processing. However, most studies use contextual embeddings with the same context length and model layer for all voxels, potentially overlooking meaningful variations across the brain. In this study, we investigate whether optimizing contextual embeddings for individual voxels improves their ability to predict brain activity during reading. We optimize embeddings for each voxel by selecting the best-predicting context length, model layer, or both. We perform this optimization with two different types of stimuli (isolated sentences and narratives), and quantify the performance gains of optimized embeddings over standard fixed embeddings. Our results show that voxel-specific optimization substantially improves the prediction accuracy of contextual semantic embeddings. These findings demonstrate that voxel-specific contextual tuning provides a more accurate and nuanced account of how the contextual semantic information is represented across the cortex.
@article{negi2025optimizing,title={Optimizing Language Model Embeddings to Voxel Activity Improves Brain Activity Predictions},author={Negi, Anuja and Tseng, Christine and Nunez-Elizalde, Anwar O and Gong, Xue Lily and Deniz, Fatma},journal={bioRxiv},pages={2025--09},year={2025},publisher={Cold Spring Harbor Laboratory},}
Brain-Informed Fine-Tuning for Improved Multilingual Understanding in Language Models
Anuja Negi, Subba Reddy Oota, Anwar O Nunez-Elizalde, Manish Gupta, and
1 more author
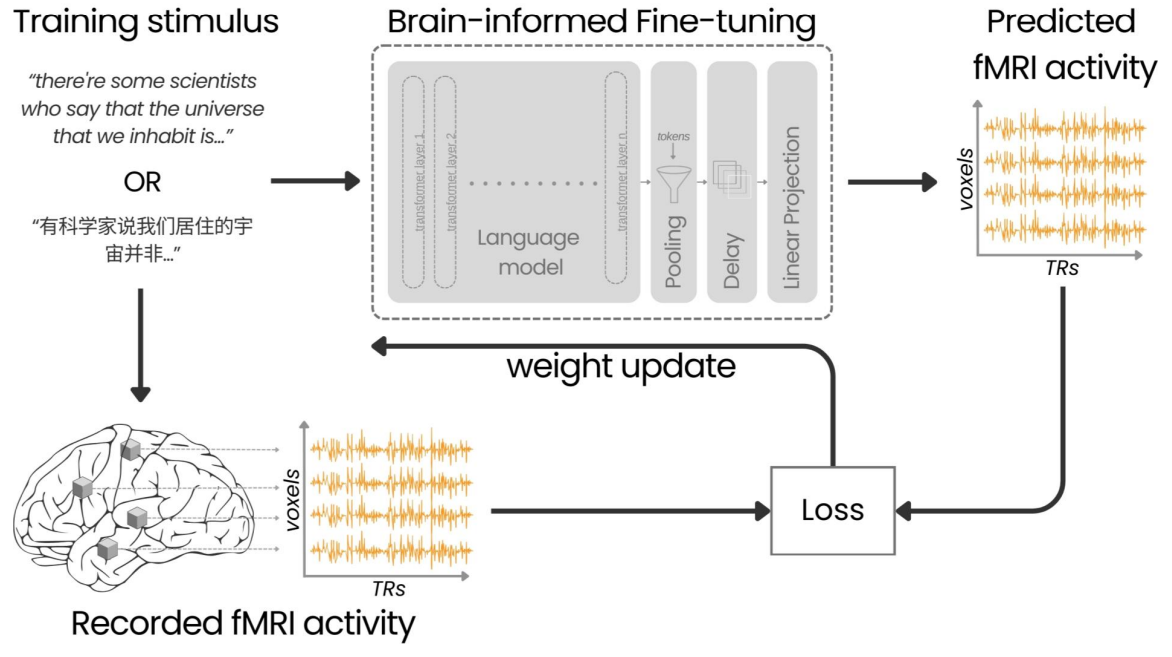
Recent studies have demonstrated that fine-tuning language models with brain data can improve their semantic understanding, although these findings have so far been limited to English. Interestingly, similar to the shared multilingual embedding space of pretrained multilingual language models, human studies provide strong evidence for a shared semantic system in bilingual individuals. Here, we investigate whether fine-tuning language models with bilingual brain data changes model representations in a way that improves them across multiple languages. To test this, we fine-tune monolingual and multilingual language models using brain activity recorded while bilingual participants read stories in English and Chinese. We then evaluate how well these representations generalize to the bilingual participants’ first language, their second language, and several other languages that the participants are not fluent in. We assess the fine-tuned language models on brain encoding performance and downstream NLP tasks. Our results show that bilingual brain-informed fine-tuned language models outperform their vanilla (pretrained) counterparts in both brain encoding performance and most downstream NLP tasks across multiple languages. These findings suggest that brain-informed fine-tuning improves multilingual understanding in language models, offering a bridge between cognitive neuroscience and NLP research. We make our code publicly available.
@article{negi2025brain,title={Brain-Informed Fine-Tuning for Improved Multilingual Understanding in Language Models},author={Negi, Anuja and Oota, Subba Reddy and Nunez-Elizalde, Anwar O and Gupta, Manish and Deniz, Fatma},journal={bioRxiv},pages={2025--07},year={2025},publisher={Cold Spring Harbor Laboratory},}
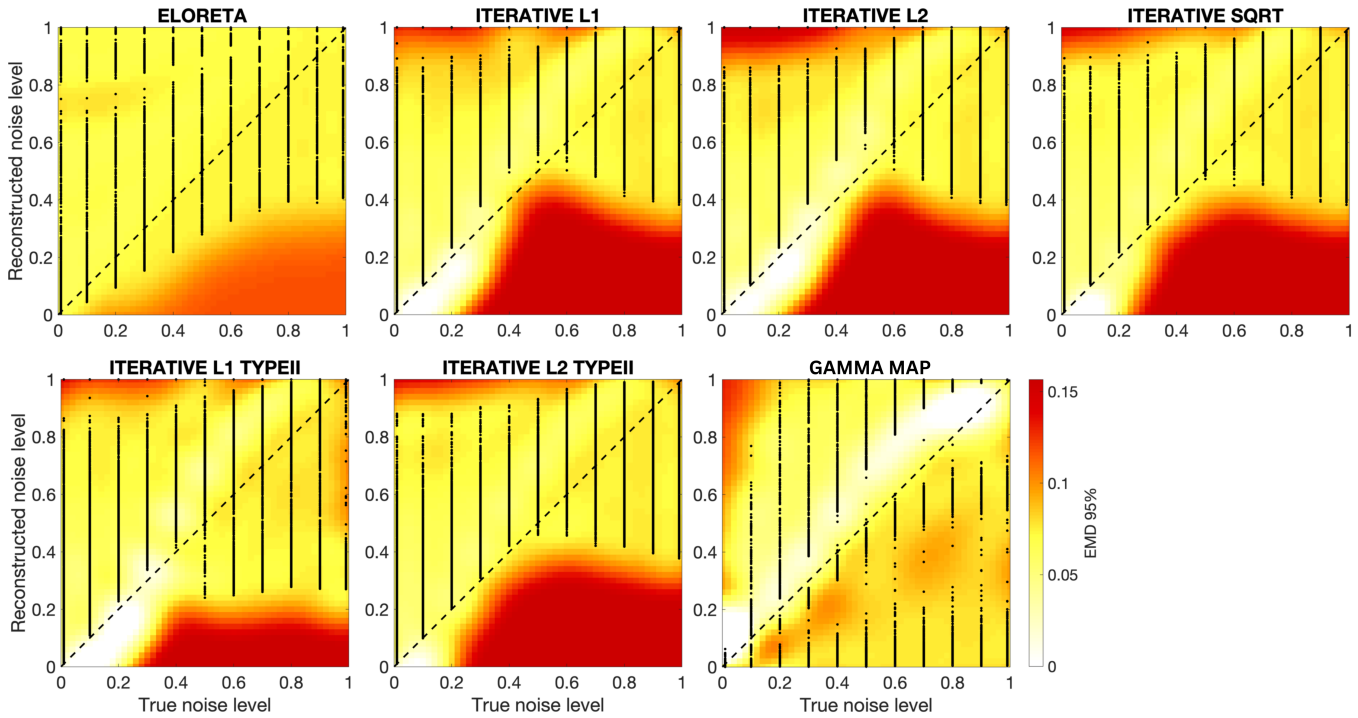
How forgiving are M/EEG inverse solutions to noise level misspecification? An excursion into the BSI-Zoo
Anuja Negi, Stefan Haufe, Alexandre Gramfort, and Ali Hashemi
@article{negi2025forgiving,title={How forgiving are M/EEG inverse solutions to noise level misspecification? An excursion into the BSI-Zoo},author={Negi, Anuja and Haufe, Stefan and Gramfort, Alexandre and Hashemi, Ali},journal={bioRxiv},pages={2025--03},year={2025},publisher={Cold Spring Harbor Laboratory},}
2024
The Virtual Brain links transcranial magnetic stimulation evoked potentials and inhibitory neurotransmitter changes in major depressive disorder
Timo Hofsähs, Marius Pille, Lucas Kern, Anuja Negi, and
2 more authors
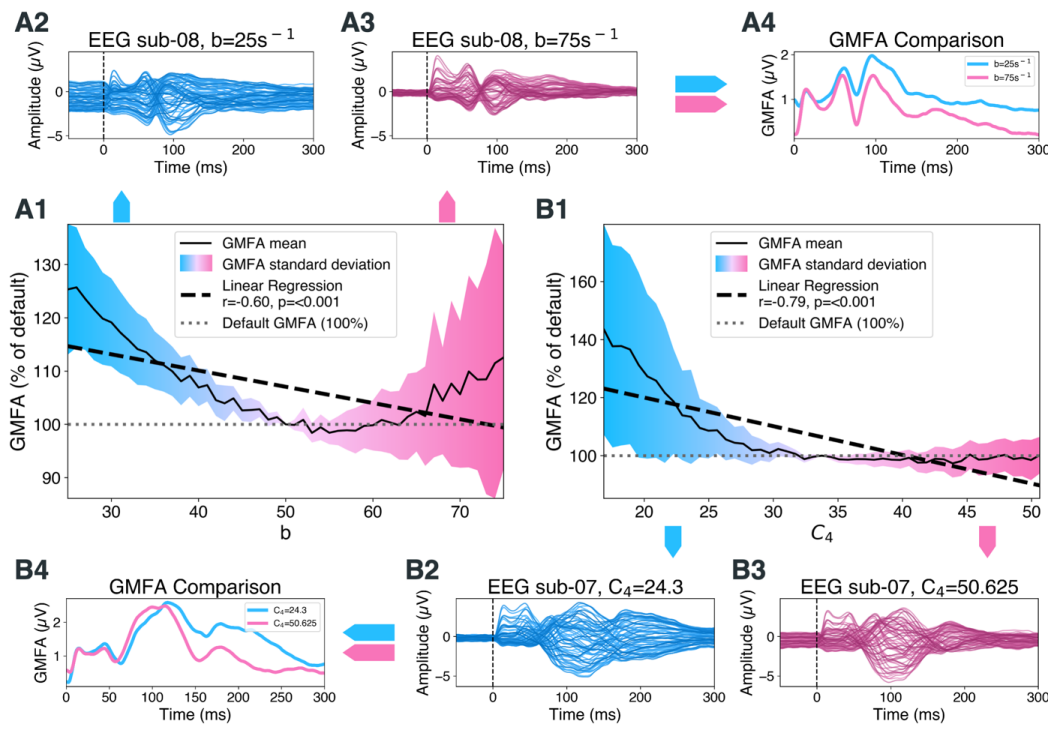
Background Transcranial magnetic stimulation evoked potentials (TEPs) show promise as a biomarker in major depressive disorder (MDD), but the origin of the increased TEP amplitude in these patients remains unclear. Gamma aminobutyric acid (GABA) may be involved, as TEP peak amplitude is known to increase with GABAergic activity, but paradoxically MDD patients exhibit reduced GABA levels. We employed a computational modeling approach to investigate this contradiction. Methods Whole-brain simulations in ‘The Virtual Brain’ (thevirtualbrain.org), employing the Jansen and Rit neural mass model, were optimized to simulate TEPs of healthy individuals (Nsubs=20, 14 females, 24.5±4.9 years). To mimic MDD, a GABAergic deficit was introduced to the simulations by altering one of two selected inhibitory parameters, the inhibitory synaptic time constant b or the number of inhibitory synapses C4. The TEP amplitude was quantified and compared for all simulations. Results Both parameters, the inhibitory synaptic time constant (r=-0.6, p<0.001) and the number of inhibitory synapses (r=-0.79, p<0.001), showed a significant negative linear correlation to the TEP amplitude. Thus, under local parameter changes, we were able to alter the TEP amplitude towards pathological levels, i.e. creating an MDD-like increase of the global mean field amplitude in line with empirical results. Conclusions Our model suggests specific GABAergic deficits as the cause of increased TEP amplitude in MDD patients, which may serve as therapeutic targets. This work highlights the potential of whole-brain simulations in the investigation of neuropsychiatric diseases.
@article{hofsahs2024virtual,title={The Virtual Brain links transcranial magnetic stimulation evoked potentials and inhibitory neurotransmitter changes in major depressive disorder},author={Hofs{\"a}hs, Timo and Pille, Marius and Kern, Lucas and Negi, Anuja and Meier, Jil Mona and Ritter, Petra},journal={bioRxiv},pages={2024--11},year={2024},publisher={Cold Spring Harbor Laboratory},}
2022
A benchmark for prediction of psychiatric multimorbidity from resting EEG data in a large pediatric sample
Nicolas Langer, Martyna Beata Plomecka, Marius Tröndle, Anuja Negi, and
3 more authors
Psychiatric disorders are among the most common and debilitating illnesses across the lifespan and begin usually during childhood and adolescence, which emphasizes the importance of studying the developing brain. Most of the previous pediatric neuroimaging studies employed traditional univariate statistics on relatively small samples. Multivariate machine learning approaches have a great potential to overcome the limitations of these approaches. On the other hand, the vast majority of existing multivariate machine learning studies have focused on differentiating between children with an isolated psychiatric disorder and typically developing children. However, this line of research does not reflect the real-life situation as the majority of children with a clinical diagnosis have multiple psychiatric disorders (multimorbidity), and consequently, a clinician has the task to choose between different diagnoses and/or the combination of multiple diagnoses. Thus, the goal of the present benchmark is to predict psychiatric multimorbidity in children and adolescents. For this purpose, we implemented two kinds of machine learning benchmark challenges: The first challenge targets the prediction of the seven most prevalent DSM-V psychiatric diagnoses for the available data set, of which each individual can exhibit multiple ones concurrently (i.e. multi-task multi-label classification). Based on behavioral and cognitive measures, a second challenge focuses on predicting psychiatric symptom severity on a dimensional level (i.e. multiple regression task). For the present benchmark challenges, we will leverage existing and future data from the biobank of the Healthy Brain Network (HBN) initiative, which offers a unique large-sample dataset (N = 2042) that provides a wide array of different psychiatric developmental disorders and true hidden data sets. Due to limited real-world practicability and economic viability of MRI measurements, the present challenge will permit only resting state EEG data and demographic information to derive predictive models. We believe that a community driven effort to derive predictive markers from these data using advanced machine learning algorithms can help to improve the diagnosis of psychiatric developmental disorders.
@article{langer2022benchmark,title={A benchmark for prediction of psychiatric multimorbidity from resting EEG data in a large pediatric sample},author={Langer, Nicolas and Plomecka, Martyna Beata and Tr{\"o}ndle, Marius and Negi, Anuja and Popov, Tzvetan and Milham, Michael and Haufe, Stefan},journal={NeuroImage},pages={119348},year={2022},publisher={Elsevier},}
2020
RDA-UNET-WGAN: an accurate breast ultrasound lesion segmentation using wasserstein generative adversarial networks
Anuja Negi, Alex Noel Joseph Raj, Ruban Nersisson, Zhemin Zhuang, and
1 more author
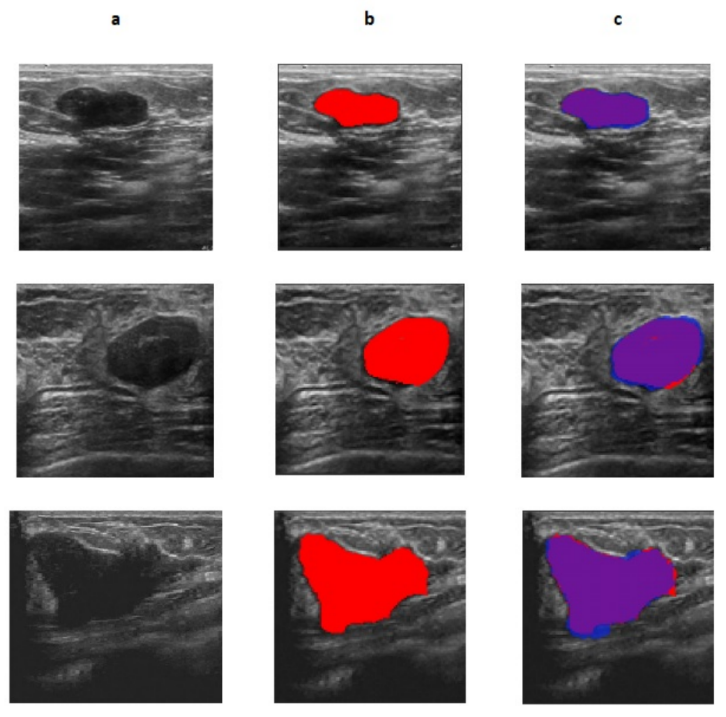
Early-stage detection of lesions is the best possible way to fight breast cancer, a disease with the highest malignancy ratio among women. Though several methods primarily based on deep learning have been proposed for tumor segmentation, it is still a challenging problem due to false positives and the precise boundary detection required for segmentation. In this paper, we propose a Generative Adversarial Network (GAN) based algorithm for segmenting the tumor in Breast Ultrasound images. The GAN model comprises of two modules: generator and discriminator. Residual-Dilated-Attention-Gate-UNet (RDAU-NET) is used as the generator which serves as a segmentation module and a CNN classifier is employed as the discriminator. To stabilize training, Wasserstein GAN (WGAN) algorithm has been used. The proposed hybrid deep learning model is called the WGAN-RDA-UNET. The model is assessed with several quantitative metrics and is also compared with existing methods both quantitatively and qualitatively. The overall Accuracy, PR-AUC, ROC-AUC and F1-score achieved were 0.98, 0.95, 0.89 and 0.88 respectively which are better than most conventional deep net models. The results also showcase the shortcomings of CNN, RDA U-Net and other models and how they can be rectified using the WGAN-RDA-UNET model.
@article{negi2020rda,title={RDA-UNET-WGAN: an accurate breast ultrasound lesion segmentation using wasserstein generative adversarial networks},author={Negi, Anuja and Raj, Alex Noel Joseph and Nersisson, Ruban and Zhuang, Zhemin and Murugappan, M},journal={Arabian Journal for Science and Engineering},volume={45},number={8},pages={6399--6410},year={2020},publisher={Springer},}
2018
Eye state detection for use in advanced driver assistance systems
Shubham Sharma, Anuja Negi, Shantanu Singh, Dinesh Samuel Sathia Raj, and
3 more authors
In International Conference on Recent Trends in Advance Computing (ICRTAC) 2018
Most automobiles lack reliable smart systems that can constantly track the driver’s behaviour and raise alarms as required. Extant systems are either too slow or not robust enough to cope with different types of drivers and conditions. In this paper, a robust system to continuously track the driver’s eye and detect its state (open/close) is proposed. Frames from a live camera feed are constantly processed. Viola Jones algorithm, using Haar filters extracts the eye. The extraction is efficient with and without spectacles (translucent) and the system can even estimate the Region of Interest (RoI) where it is most likely to find the eye in the event that no eyes are explicitly detected. A trained CNN model using the LeNet architecture classifies the extracted eyes. The rate at which predictions are made is also higher than existing systems. The system raises an alarm if, after analysing the data points, it detects any anomalies.
@inproceedings{sharma2018eye,title={Eye state detection for use in advanced driver assistance systems},author={Sharma, Shubham and Negi, Anuja and Singh, Shantanu and Raj, Dinesh Samuel Sathia and Graceline, Jasmine S and Vaidehi, V and Ganesan, Subramaniam},booktitle={International Conference on Recent Trends in Advance Computing (ICRTAC)},pages={155--161},year={2018},organization={IEEE},}
Gini Index and Entropy-Based Evaluation: A Retrospective Study and Proposal of Evaluation Method for Image Segmentation
Anuja Negi, Shubham Sharma, and J Priyadarshini
In International Conference on Nanoelectronics, Circuits and Communication Systems 2018
Image segmentation is an old and ever-growing field in computer vision. Several image segmentation algorithms with diverse approach methodologies have been proposed over the years. As a result, several evaluation criteria have also been proposed. Many of these segmentation and evaluation methods are based on the famous Gini index. Several have tried using entropy values as well. Methods based on these have been tuned and modified for betterment over the years. This paper does a thorough literature survey on the growth and usage of Gini index and entropy for segmentation and primarily evaluation. Realizing the potential as well as the limitations, the paper proposes an evaluation criteria based on Gini index and entropy. The proposed algorithm uses the concept of maximum intra-region homogeneity and inter-region heterogeneity in segments to evaluate a segmentation technique. Evaluation is done on segments as seen by the segmentation technique in the original input image.
@inproceedings{negi2018gini,title={Gini Index and Entropy-Based Evaluation: A Retrospective Study and Proposal of Evaluation Method for Image Segmentation},author={Negi, Anuja and Sharma, Shubham and Priyadarshini, J},booktitle={International Conference on Nanoelectronics, Circuits and Communication Systems},pages={239--248},year={2018},organization={Springer},}